2020.06.25

はじめに
データサイエンスの基盤とは何か
これからデータサイエンスや機械学習に取り組み始める企業、もしくはAIプロジェクトの担当となったが何が必要なのかが分からない人、AI技術を勉強してきた就職前の学生を対象にデータサイエンスの基盤について紹介する。ここでの“データサイエンスの基盤”とは「OSはUNIXが必要だ、Python環境ではこのライブラリが必要だ」などといったエンジニアリングの計算機環境ではなく、機械学習の開発業務や分析業務を進めるうえで、必要となるデータ構造やデータ表現、業務環境として紹介する。この記事では、「こうした話は案件によるから一概に言えない」というデータサイエンティスト側の声と「どんなデータがあれば始められるのかを知りたい」という経営者や企業の上層部の声の間に存在する両者の課題を解消するべく、可能な限り言語化を意識して総括する。
ツール導入が招くデータサイエンスの障壁
様ざまな業務ツールの導入により業務課題を解決することは企業にとってすぐに効果が得られるため、日々導入に向けて議論されている。実はこのツール導入の決定が社内のデータサイエンティストにとって次の一手を打つ時に、思わぬ障壁を招くことがある。
「一旦ツールで解決できるならそれでいいじゃないか、ツールでできるところはやってからその次の一手となる研究をしたらいい」
こうした意見は一見、合理的に見えるが必ずしもそうではない。例えば、ある企業が“業務課題1”を解決するためにツール導入の決定をしたとする。そして、別の“業務課題2”に対策を打つべく、データサイエンティストやAIエンジニアを集めて新しいシステムの開発計画を立てる。この時、“業務課題1”と“業務課題2”が同じ業務領域である場合、コストパフォーマンス面や開発段階でトラブルが発生しやすい状況になる。
なぜこのようなトラブルが発生するのか、そのメカニズムをとらえるためにはデータ分析の大まかなステップについて把握する必要がある。
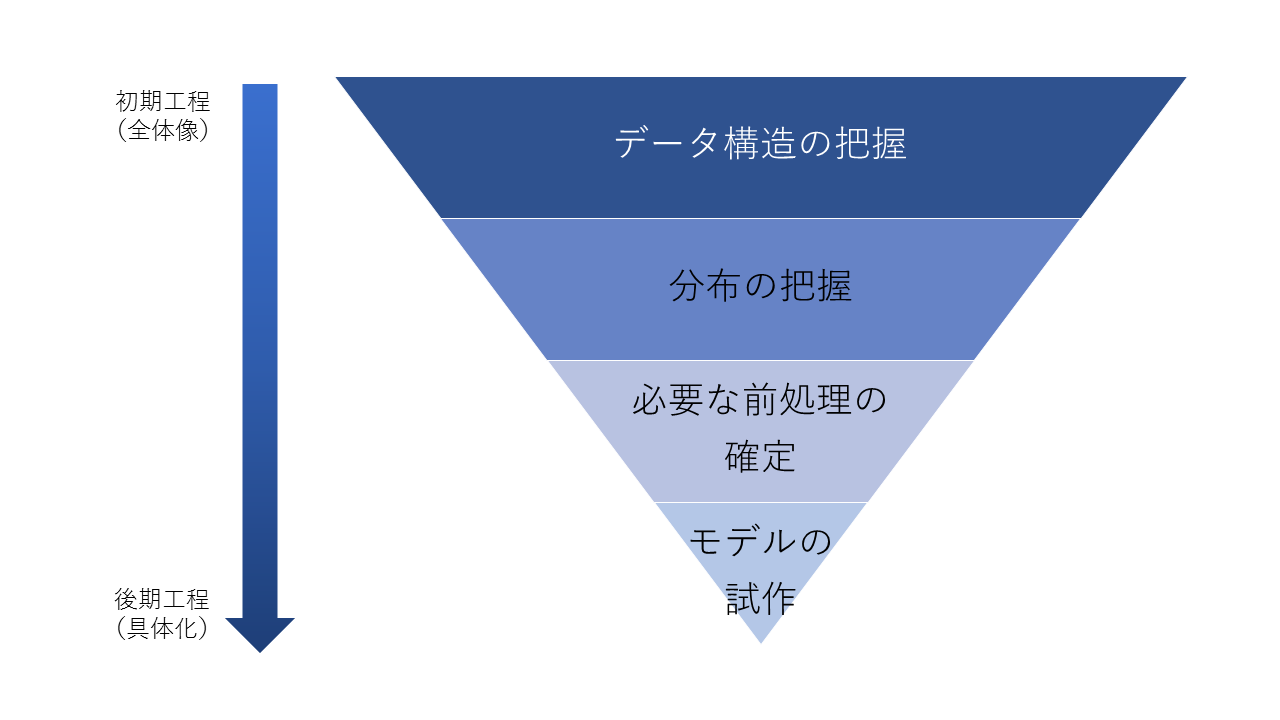
(図1:機械学習システムが出来るまでの大まかな流れ)
データ分析や機械学習のモデルによる解決策は、ほぼ確実にデータから作成される。そして分析をするためにもデータを取得、抽出することから始めるのがほとんどだ。(図1)機械学習モデリングやデータ分析の大まかなステップは次のようなものだ。
機械学習モデリングやデータ分析のステップ
- 取得できるデータの構成を把握(情報項目の整理)
- データを取得し、データのバリエーションと分布を整理する(基礎調査/基礎分析)
- データに含まれる課題を整理し対処するロジックを開発しデータを整形する
(前処理/データクレンジング/欠損値補間など) - 整形されたデータを基にモデルの試作(特徴量探索などを含む)、分析を進める
- 最初に得られたデータセットを教師データ/テストデータに分けて目標となる性質が確認できるモデルを作る
- 最初に得られたデータセットとは別に最新のデータ取得を行い、業務適用と同じような条件の下データを入力していき、モデルの品質などを検証する
- モデルが適合しなければ2~6を繰り返す
(プロトタイピング&Proof of Concept※以下PoC) - モデル化が完了したら、業務適用に向けた製品化に向けた製造をする
- 業務利用のためのシステムへ組み込む
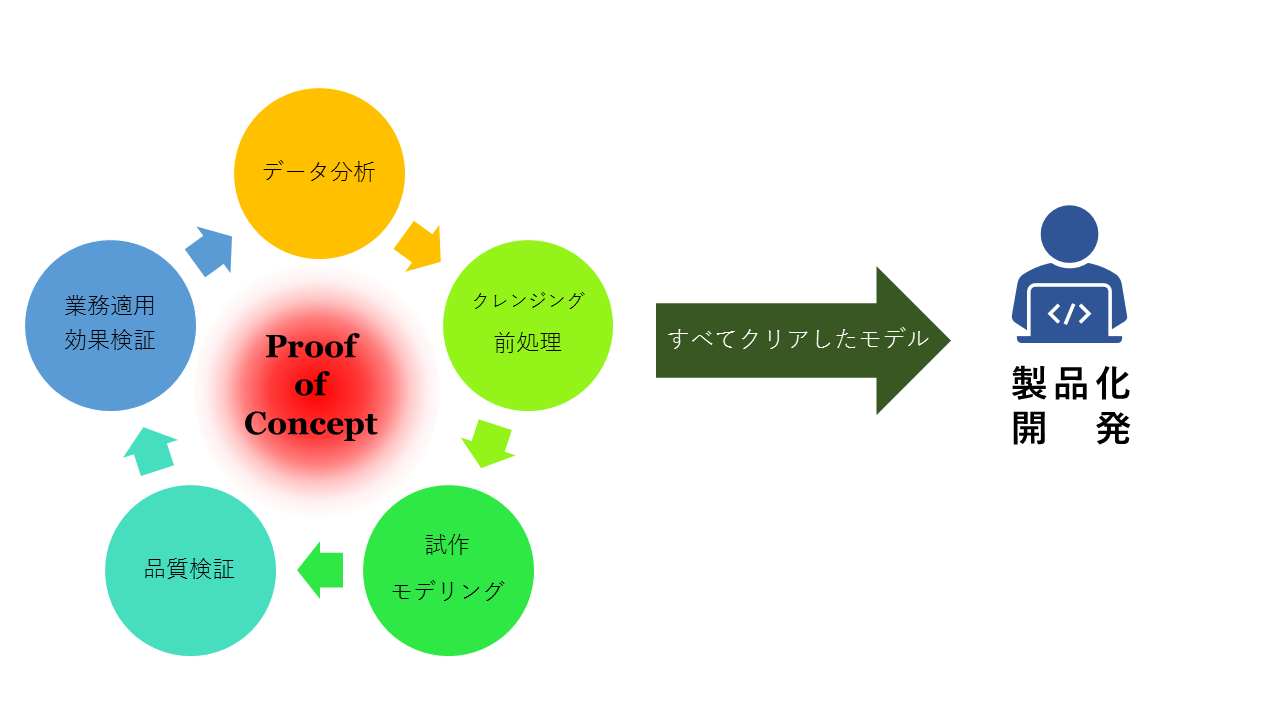
(図2:AIシステムが出来るまでにデータサイエンティストがやっていること)
詳細な業務の進め方や業務範囲、体制などについては業種や各企業によって多少異なるが、PoC以降の業務適用に関しては他のチームや専門部隊で開発することも多い。そのため、図2の左側のサイクルにあるように、分析~前処理~モデリング~評価までを回すことが主業務となることもある。この工程の中で何が問題になるかというと、ほとんどの開発は「データを集める/抽出する」ところから始まることにある。
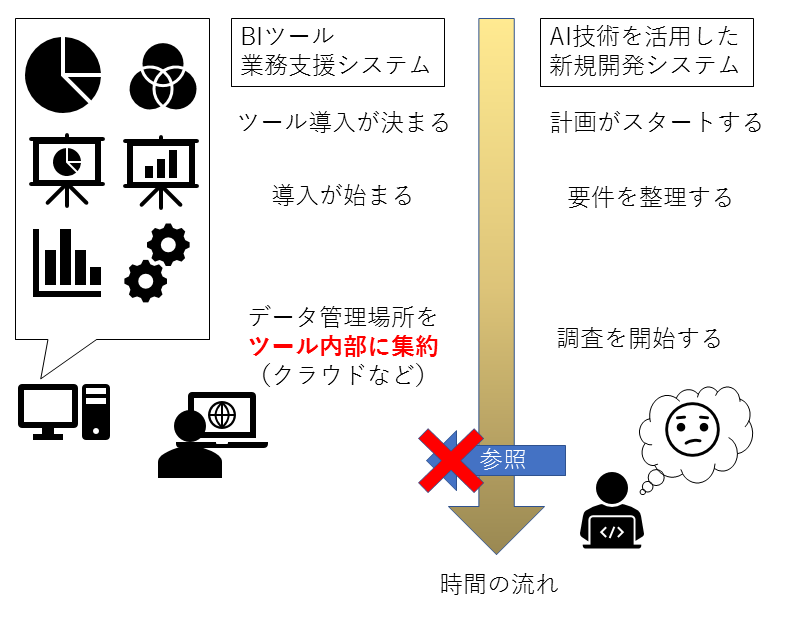 (図3:ツール導入とデータサイエンスがぶつかる場合の流れ)
(図3:ツール導入とデータサイエンスがぶつかる場合の流れ)
業務支援ツールの導入とAIシステムの開発を同時にスタートさせると、当然ツール導入の方が早い。そして開発基盤は構想やコンセプト検証、議論を通してからスタートするため、先に導入されたツールを通してデータを抽出する、あるいはさらに外部からデータを追加してから研究開発を始めることになる。ほとんどの場合、先に導入されたツールと同じデータを保持することになるので費用対効果が悪い。さらに導入されたツールというのは、多くの場合エンタープライズ製品なので、表示速度などのパフォーマンス向上やデータを保持するストレージの節約などを理由に、データ解析に通用する粒度でデータを保持しておらず、集計・加工したデータのみを持っていることが多い。また、ツールがデータ取得を前提に稼働している場合、研究開発を作るために生データの取得もままならない状態(稼動しているツールに対して影響が出るから取得制限がかかる等)で研究開発が遅れる、という問題すら発生する。
これが合理的か、と言われるとどうだろうか。先に導入されたツールが最初からデータ分析に対応できる粒度で保持していれば問題ないが、残念ながらこうした問題は至るところで発生している。またツールが十分にデータサイエンスを想定した設計をされていない場合、ツールはパソコン1台のメモリ上で処理できる量しか保持せず、古いデータを破棄していて取り返しがつかない、なんてことさえもある。
ツール導入検討の際、同じ業務領域で研究開発を仕掛けるならばひと度システムに慣れている機械学習エンジニア(データサイエンティスト)か機械学習の要件を理解しているSEなどのエンジニアのレビューを通すだけでもこうしたトラブルは大きく減らせるだろう。
問題は「同時発生の時に、想定外な範囲でスケジュールが乱されること」にあるため、業務支援ツールの導入とAIシステムの開発が同時進行でない場合はそこまで深く考える必要はない。
まとめ
これからデータサイエンスや機械学習に取り組み始める企業やプロジェクトの担当者、就職前の学生を対象にデータサイエンスの大まかな流れを紹介し、ツール導入とシステム開発が同時発生した場合にツール導入が招くトラブルのリスクについて紹介した。学生の間には経験しないことではあるが、企業は常に同時に複数の事象が進む。ひとつのプロジェクトを進めようとしても、よく情報整理をしておかなければこうしたトラブルが思わぬところから出てくるため、注意が必要だ。さて、データサイエンティストの周辺で起こるトラブルについてここまで述べてきた。しかしながら、先ほどの話の中で議論できていない点がある。ツールで保持されているデータが分析や機械学習の用途に耐えられない、という点だ。では、ここで述べられる「データ解析に通用する粒度」とは何だろうか?データの粒度というものを形作る要素を大きく分けると(「データの粒度」の分け方についての議論は様ざまだが)、構造と種類(バリエーション)という観点で整理することができる。この詳細は次回に紹介しよう。