2020.06.25

機械学習の入力となるデータ構造とは
データベースについて設計に従事していると「正規化」について必ず検討・考察する必要が出てくる。正規化とはデータの冗長な表現(重複したデータ)を無くし、整合性を持ったデータベースの設計のことだ。正規化により、同じデータの追加や更新、削除を繰り返し操作することなく編集できるため、データの不整合や喪失を防ぎ、メンテナンス性を高められる。正規化には第1~第5正規形およびボイスコッド正規形があるが、第5正規形がすべてのシステムに適合するわけではなく、数字自体に上位の性質を持っているものではない。そのため、実際のシステム開発では業務ロジックなどに合わせて適切な正規形が選択される。正規化がもたらすメリットの中でも特に重要な目的は、データの不整合や喪失の回避、およびメンテナンス向上を目的としたデータの加工である。具体的な例を以下に紹介する。
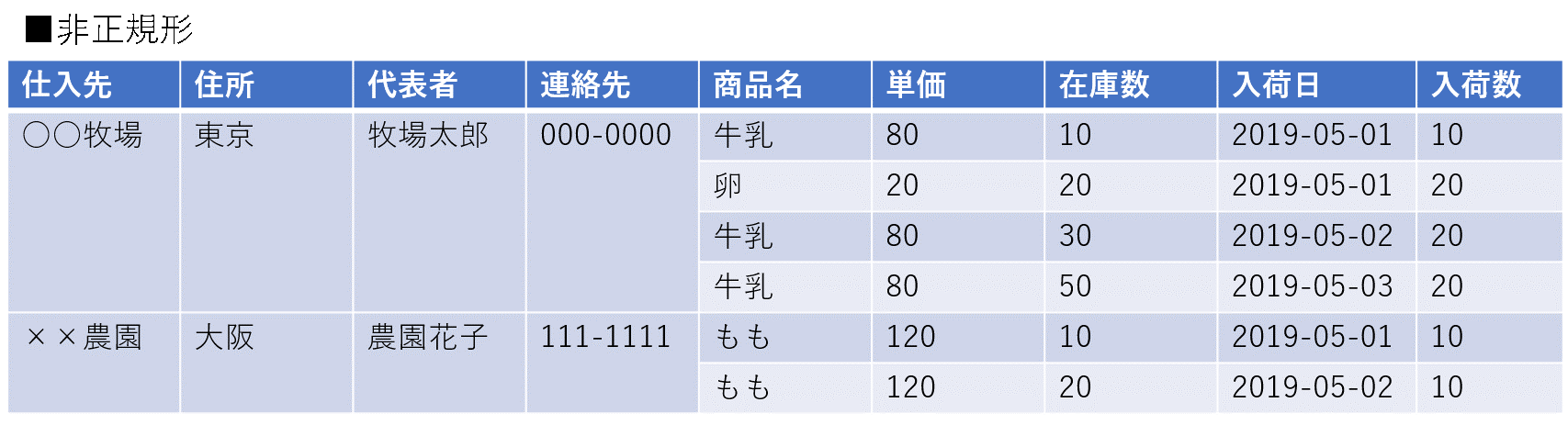
(表1:非正規形のデータ構造)
ここでは簡単な説明にとどめるが、非正規形とは繰り返し項目(結合された部分)を持っているような構造だ。JavaScript Object Notaion (JSON)形式やExcelファイルでよくみられる構造をしているが、このままデータベースに登録されることはまずない。そこで、この繰り返し項目を展開した構造に変換する。
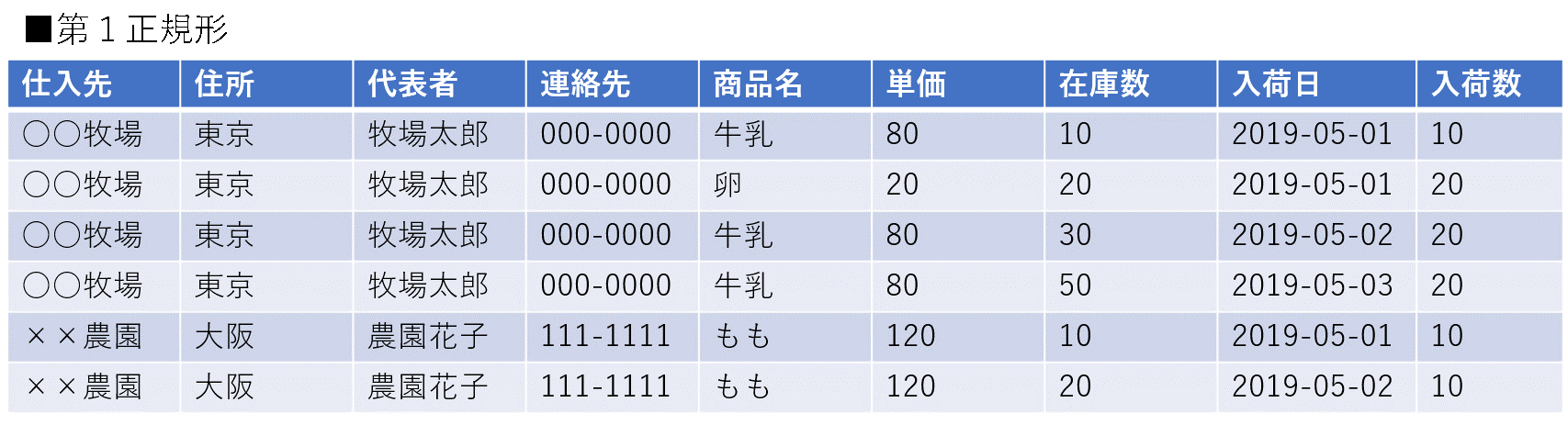
(表2:第1正規形のデータ構造)
厳密な第1正規形は算出可能な項目(表2の場合は在庫数の項目が該当する)は削除されるが、機械学習で使用する形式はこの形だ。機械学習では入力データのほとんどがベクトルとして表現されている。非構造化データを扱う問題であっても、ベクトル表現に変換していることがほとんどである。一般的な分析業務ではデータは属性値、説明変数などの数値的/カテゴリカルな変数の配列として入力されるため、基本的にはどんなデータもベクトルである。ベクトルをひとつの行として管理した時、データはデータベースで格納することが可能である。この情報は実は第1正規形と同じデータ構造である。
さらにエンタープライズ製品として実装されるデータベースの多くは第2~第3正規形のデータ構造として管理されていることが多い。そのため、機械学習の教師データをデータベースから作成する場合は正規化されたデータを結合しながら第1正規形に変換して使用する。
データの中身が主軸となるが、業務システムなどから連携をして一時的なデータストアを機械学習やデータサイエンスのために構築する際、こうした第1正規形で管理することが「機械学習の入力から見たときに加工を必要とせず、ファイルと同じようにデータを取得する構造」として実現できる。「加工が必要ない=データハンドルが容易である」ことと「データアクセスへの速度に優れている」ことの観点で議論した場合、第1正規形データ構造による管理が最も適している。
この方法はデータ管理のコスト面では保存するデータ量が多いため割高になる。一方で計算処理負荷は少ないので処理能力を理由とした分散処理システムを構築する必要はない。データ転送速度を目的とした分散システムのHadoopなどが有効だ。しかしながらデータ維持の費用が気になるためにコストをなるべく抑えたいというニーズも存在するため、その場合は高次の正規化処理が必要であり、その場合は結合演算などで大量の処理が発生する。その時間コストを処理能力で補いたい場合はBigQueryなどのクラウド上で展開される分散処理を基盤としたデータベースが有効だ。データ維持管理費自体は低く設計されているが、処理量に対して従量課金となる。
機械学習の入力となるデータの種類(バリエーション)とは?
分析手法は人それぞれなので一概に言えるものではないものの、データ分析を行うにはまず、そのデータの分布を眺めることから始まる。近年の深層学習を始めとする機械学習アプローチは統計的機械学習と呼ばれ、統計処理を内包している。「実際に生じる事象を教師データが内包していること」を前提にアルゴリズムが構築されているため、いわゆる「事実の網羅性」が重要となるからだ。例えば、データの偏りや欠落がどこにあり、どの程度の量なのかを把握しない事には、分析した結果の解釈が大きく変わってくる。統計第一情報である平均と標準偏差で性質を議論したり、推論を展開しながら傾向分析などで帰結を得たりする工程で用いられる多くの手法が正規分布を仮定していることが多い。無論、正規分布を想定した手法は正規分布以外の分布には使えない。そのため、まず分布の形がどうなっているかを整理することは極めて重要だ。
さらに機械学習のモデルを作成するためには目的変数と説明変数の対応関係を整理するのも重要である。機械学習において重要な要素がノイズとして扱われると予測精度が極端に落ちることに繋がるため、こうした要素の全体感を把握できるデータになっているかが機械学習に必要なデータ要件となる。具体的には、1時間ごとの予測を行うときに1日単位で集計されたデータでは対応できないし、エリア単位で管理されている業務の分析は部署単位の集計表から得られない。また、競合他社のリリースがいつ入るかを予測したり、半年後にどんなイノベーションが起こるかを営業成績の推移データから予測したりすることはできない。
機械学習は「すべての起こりうる事象はデータの中に閉じている」ことが想定されており、少なくとも最大幅のバリエーションを含んでいることが重要である。誰も初めて遭遇する事象について予測することはできないように、機械学習も完全な未知の事象を予測することはできない。あくまで教師データで想定される範囲内において未知データへ柔軟な適合をするのが機械学習である。
ここからわかるように変数(情報要素)が欠落していないこと(もしくは補えること)、集計処理されてないデータに近いこと、実現したい機能が既に観測された事実に基づいていること(データとして存在していること)が重要で、どのくらい事実を網羅しているかが鍵となる。これが「事実の網羅性」である。
まとめ
「分析や機械学習の用途に耐えられるデータ」とはどのようなものかについて、データ構造とデータの種類の2つの観点で紹介した。機械学習では第1正規形としてデータが表現されている状態が教師データの構造であるが、冗長な表現であるため、コストバランスによって適切な構造を保持するべきであることを紹介した。また、データの種類という観点では、機械学習は「すべての起こりうる事象はデータの中に閉じている」ことが想定されているため、「事実の網羅性」が担保されていることが需要であることを紹介した。
今回、データまわりの環境や基盤についてできる限り言語化した情報をこの記事では提供した。これによって、データ分析に力を入れていく企業やデータサイエンティストを目指す人たちが、よりスムーズな分析業務の実現に貢献できることを願っている。