2022.05.11

robots.txtとは
robots.txtは、検索エンジンのクロールをコントロールするために設定するファイルです。クロールさせたくないURLを指定することでWebサイトの過負荷を防いだり、不要なURLにクロールする分のリソースをクロールさせたいURLへあてたりすることができます。
クロールをブロックするケースには、会員限定の情報が掲載されるURLや仕様上大量に生成されてしまう重複URLなどが考えられます。一方で、クローラによるWebサイトへの過負荷の心配がない場合やクロールのリソースを気にしなくてよい小規模なWebサイトの場合、robots.txtは必要ありません。
・注意点
本記事では、対象の検索エンジンをGoogleとして詳細を紹介しますが、Google以外のクローラもrobots.txtを参照します。この際、Googleと同じ挙動を取るとは限らないためBingやBaiduなどGoogle以外の検索エンジンのクローラをコントロールしたい場合は、個別に記述方法を確認する必要があります。
robots.txtはインデックスを拒否する手段ではない
robots.txtはクロールをコントロールするためのものであり、インデックスを拒否する手段ではありません。クロールをブロックしているURLが別のWebページからリンクされているようなケースでは、クロールせずにインデックスすることがあります。この時、検索エンジンはWebページの情報を把握していないため、検索結果では図1のような表示のされ方となります。
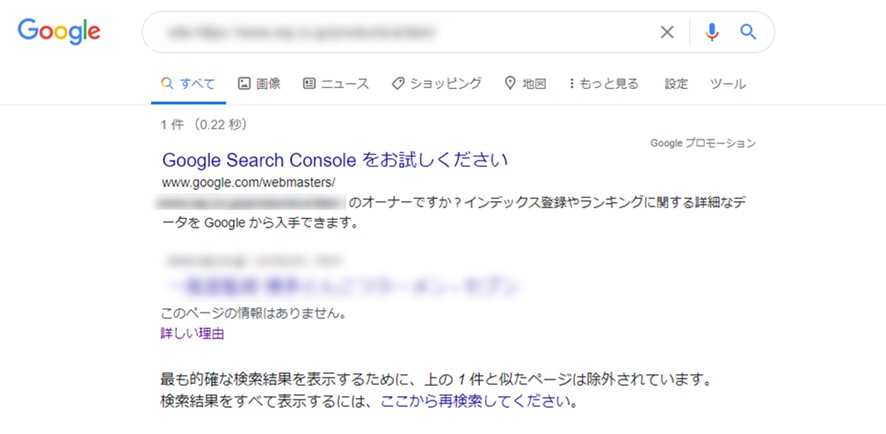
(図1:robots.txtでブロックしているページが検索結果に表示される例)
検索結果に表示させたくないURLは、noindex メタタグの利用など別の手段で検索エンジンに伝える必要がある点について注意しましょう。また、robots.txtでクロールをブロックしているURLがインデックスされてしまい、そのURLにnoindex メタタグを付与してしまうケースがありますがこれは適切な方法ではありません。noindexなどのメタタグはURLをクロールする時に検出されるため、クロールをブロックしているとnoindexが付与されていることを検索エンジンが認識しないためです。
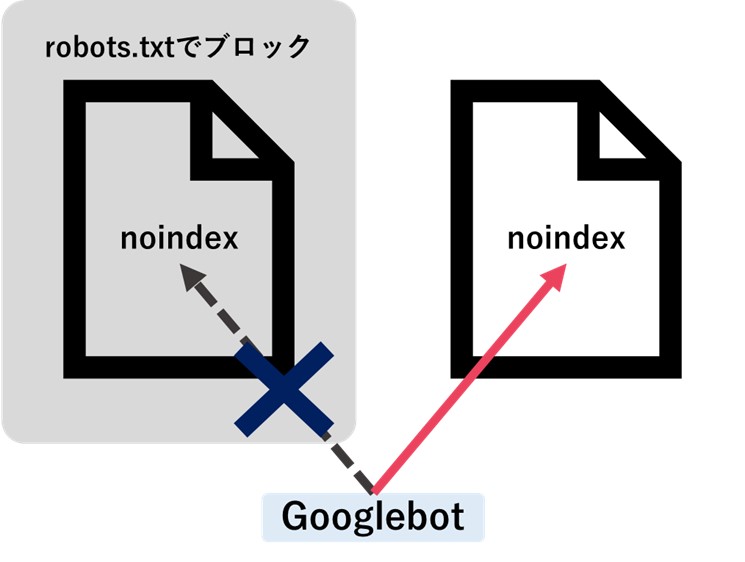
(図2:robots.txtでブロックしているとメタタグは検出されない)
あくまでもrobots.txtはクロールをコントロールするために利用するものであり、インデックスをコントロールするものではないということを把握しておきましょう。
robots.txtの書き方
robots.txtは、クロールをコントロールする指示を記載したグループをひとつ以上記載して作成します。グループには対象とするユーザーエージェントとそのユーザーエージェントに指示するルールを含めます。
・内容を作成する
Googleがサポートしているディレクティブは下記の4種類です。クローラが認識できるよう正しい文法で記載する必要があります。
・User-agent(必須)
対象とするユーザーエージェントを指定します。「Adsbot」を除くすべてのユーザーエージェントを対象とする場合は「*」、一部を対象とする場合はユーザーエージェントの名前を記載します。
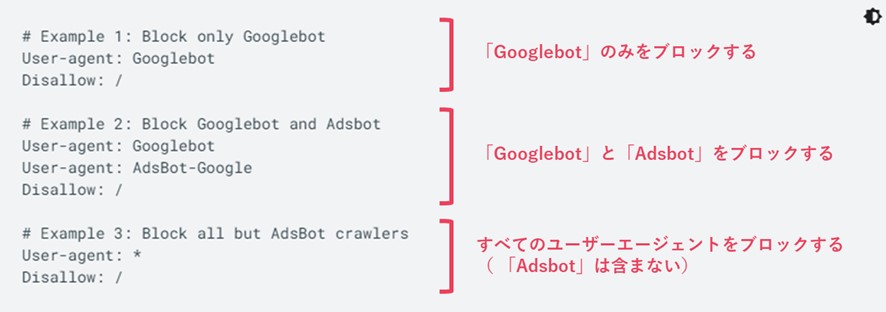
(図3:対象とするユーザーエージェントの記載例)
引用元:robots.txt ファイルを作成して送信する | Google 検索セントラル | ドキュメント | Google Developers
クローラの名前は下記のページに記載されているため、参考にしてください。
参考:Google クローラの概要(ユーザー エージェント) | Google 検索セントラル | ドキュメント | Google Developers
・Disallow(DisallowかAllowのいずれかがひとつ以上必須)
クロールを禁止するディレクトリまたはURLを指定します。以下の例では、図4の部分をブロックするイメージとなります。
| User-agent: * Disallow: /bbb/ |
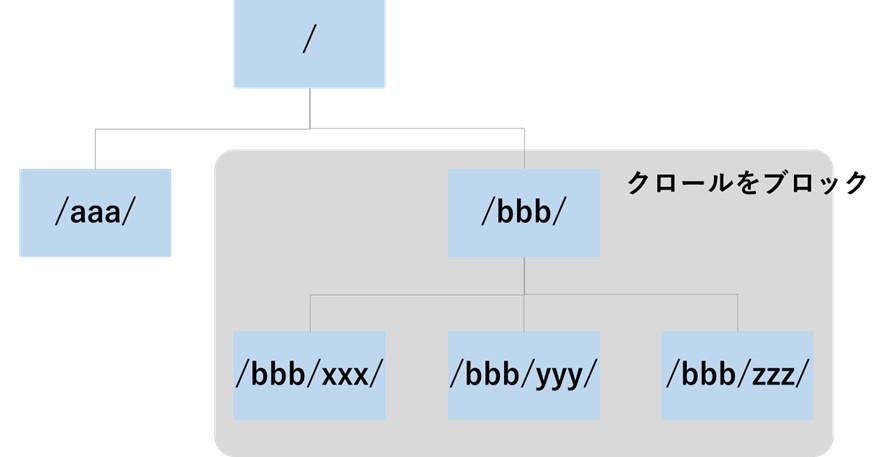
(図4:/bbb/ディレクトリ配下のURLのクロールをブロックするイメージ)
・Allow(DisallowかAllowのいずれかがひとつ以上必須)
クロールを許可するディレクトリまたはURLを指定します。Disallowでクロールをブロックした範囲に、許可したいディレクトリやURLが含まれる場合に利用します。以下の例では、図5のように[/bbb/zzz/]ディレクトリはクロールを許可する形となります。
| User-agent: * Disallow: /bbb/ Allow:/bbb/zzz/ |
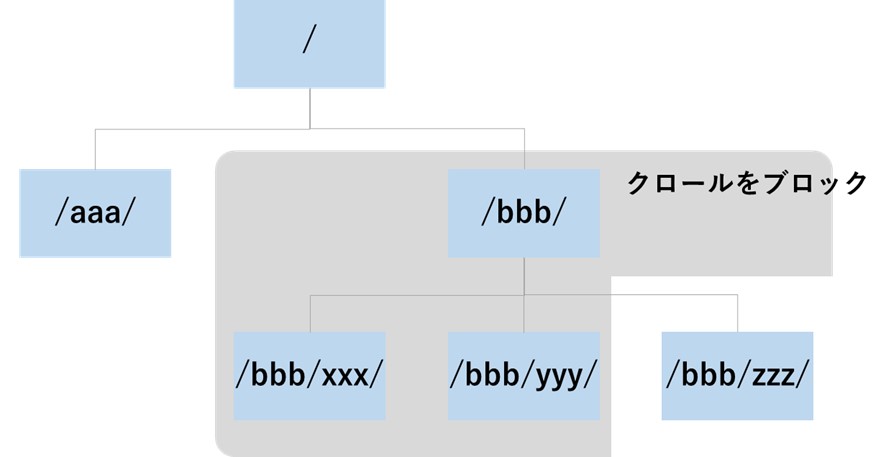
(図5:/bbb/ディレクトリの配下のURLのクロールをブロックしたうえで、/bbb/zzz/ディレクトリはクロールを許可するイメージ)
・sitemap(省略可)
対象のWebサイトのサイトマップのURLを記載します。
・文法の正誤をテストする
内容を作成できたらrobots.txt テスターを使って文法に誤りがないか確認します。意図通りにブロックできているか、URLを入力して確認することもできます。
●調査手順
1.Google サーチコンソールにログインした状態で下記のrobots.txtテスターツールを開く
2.作成したテキストを入力するとエラー数や警告数が確認可能
3.確認したいURLを入力して「テスト」を押下すると、クロールの許可状況も確認可能
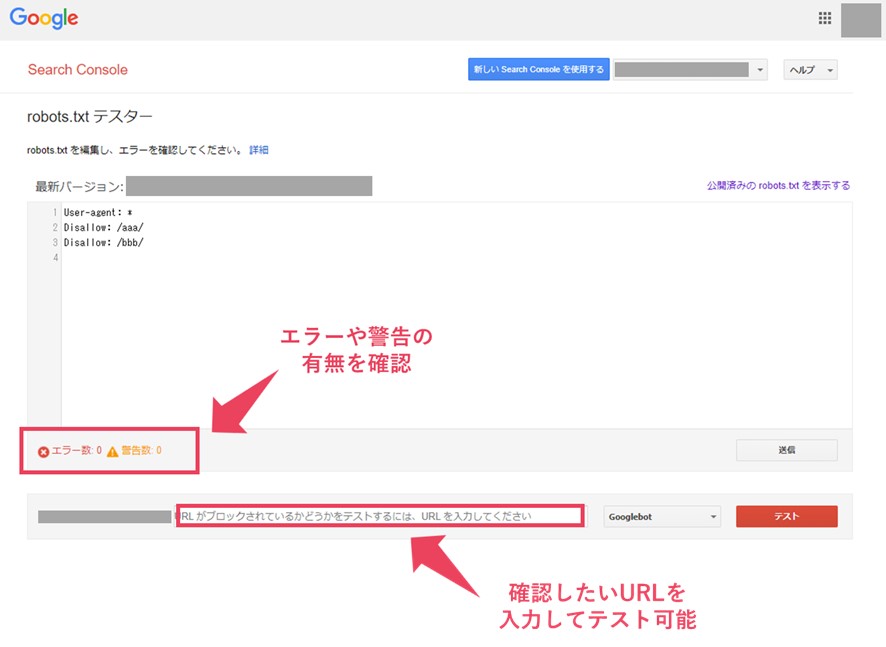
(図6:robots.txtテスターツールの利用イメージ)
参照元:Search Console - robots.txt テスター
・アップロードする
テストが完了したらアップロードします。robots.txtは下記のようなルールが定められているため、これらに従いましょう。
・ファイル名は「robots.txt」とする
・UTF-8でエンコードされたテキストファイルとする
・ルートの配下に配置する
例)OK:https://example.com/robots.txt
NG:https://example.com/aaa/robots.txt
通常はアップロードをおこなってGoogleのクローラがアクセスできる状態になっていれば何もする必要はありませんが、すぐにGoogleに認識してほしい場合には、robots.txt テスターから[送信]を押すことでGoogleの確認を促すことができます。
まとめ
robots.txtの利用はすべてのWebサイトにとって必要なものではありませんが、特に大規模サイトなどでは適切に活用することでクロールしてほしいURLにリソースをあてることができます。一方であやまった記述をしてしまうとクロールが適切におこなわれず、自然検索流入を大幅に減少させることもあるため慎重に対応することが重要です。robots.txtを使うべきか判断に悩む、記述方法がわからない、など課題をお持ちの場合は当社にお問い合わせください。
▼関連資料
